Escaping LLM piping mess with nifty engineering
In this post I’ll walk through how I upgraded a set of tangled Python notebooks—responsible for thousands of LLM calls—into a robust content-adaptation studio powered by:
- an async FastAPI pipeline,
- a disk-first Next.js frontend, and
- a small suite of custom CLI tools.
Re-engineering the stack was essential for my own sanity: the notebooks were fragile, slow to iterate on, and far too labor-intensive to babysit.
I was also facing content quality challenges that were pretty much impossible to address in the old code base, that re-engineering unlocked.
My hope is that the story also nudges you to build (or level-up) your own tooling instead of settling for one-off notebooks.
We’ll cover:
- Engineering constraints – huge text volumes, strict meaning preservation, multiple target languages.
- The original notebook setup – what worked and where it hurt.
- Pain points – why small hacks no longer cut it.
- The new architecture – key design choices, novel elements (with screenshots), and how they solve the earlier pain.
- Outcomes & takeaways – higher quality, less toil, faster experiments, and patterns you can reuse in your own LLM workflows.
Shape of the problem
Shape of the problem:
- large quantities of text that need to be processed in a very specific way:
- retain meaning of the original (no text disappearing or altered significantly)
- consistent between parts
- translated & simplified
- resulting content needs to consistently have good quality
- automatic quality assessment and quality repair (revisions)
A similar challenge would be relevant in translating legal documents, healthcare documents, etc.
Story Learner Book Adaptation needs
In my project StoryLearner I offer adapted books for language learning at a specific level. For example, “Las Aventuras de Sherlock Holmes, in A2, Spanish”.
We use LLMs for both language/level adaptation as well as for illustrations. It’s a lot of LLM calls (easily thousands for a single book), because books are long and there are many elements for a single adaptation.
A book has chapters, chapters have parts for easier reading. Each book/chapter/page has an custom illustration. Additionally, there are titles and descriptions to be adapted and transcribed.
Books are long and we want the adapted text to retain the meaning, while making the language simple (aligned with the target level), natural sounding and correct.
Trouble with a flaky, slow pipeline and hard to assess output
The pipeline was was quite a feat! It was a lot of LLM calls, built mostly in colab/jupyter notebooks.
RAW BOOK
|
v
[book_stripping]
|
v
[chapter_extraction]
|
v
[chapter_simplification] (English)
|
v
[chapter_partification] (English)
| \
| \
| ---> [illustration_generation]
|
v
[adapt] ──▶ [Lang 1]
│ [Lang 2]
│ [Lang 3]
│ [Lang 4]
│ [Lang 5]
│ [Lang 6]
|
Illustration generation was on its own a pretty interesting pipeline (more about it in a separate post!).
Here is one of the adaptation notebooks:
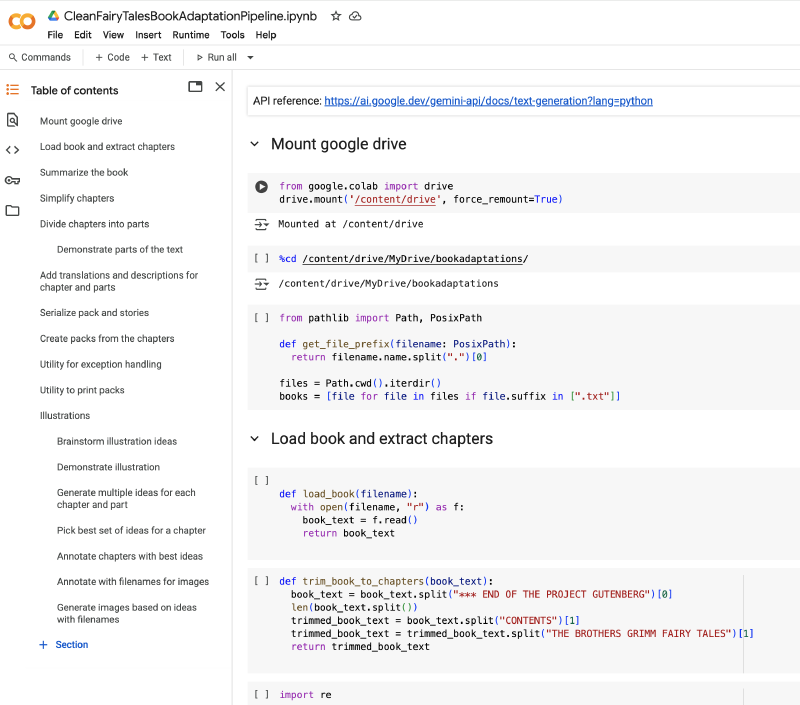
As you can see, it has its own table of contents on the side. It’s easily thousands of lines of code and prompts. And the hundreds of outputs (text and images) could make it very, very, long. To the point that it would have rendering issues.
On top of it there was:
- Separate notebook for
book_narration - Another notebook for upload to storylearner (via API).
The “pipeline” worked. It serialized partial outputs in a way that partial redos/continuations were possible, it offered decent visualization. It was adjustable (just add/tweak a notebook cell!).
However it was fragile and assessing quality/redoing content was painful and slow. And it was very frustrating to me, especially since the quality was important to my partners (language schools).
Main pain points
- LLM reliability issues (no resources, surprise safety controls kicking in, running out of quota or LLMs not following instructions) broke downstream steps.
- The adaptation process was slow, it wasn’t taking advantage of paralellization well
- The pipeline was already so brittle enough that meaningful experiments were nearly impossible
- Colab/notebooks encouraged slapping things together instead of proper engineering with encapsulation and tests
- Python notebooks having rendering bugs because they were so long and had so many outputs (large text/many images)
- Low confidence in language level, name/format consistency, and preserved meaning without having a strict review/repair process and having some examples of problems with quality.
- Reviewing 60+ chapters across six languages was slow and manual - was infeasible for me.
- A copy of an adaptation notebook per book (for visualization/auditability) was duplicating the code and making it harder to maintain
New Content Adaptation Tools
I haven’t built everything at once. I started with a frontend using the existing disk format of book adaptations, then as it was easier to see what was going on, I progressively built more and more backend migrating specific functionalities. Fast API gives a nice UI out of the bat to call APIs, which was nice for trying things out. But the workflows were simply to long to drive them by hand, so that is how CLI tools came to be.
CLIs/Frontend were in big part written by copilot coding agent. I also extensively discussed the component prompts with LLMs 😀.
-
Backend –
bookadaptation(FastAPI)- all functionality behind endpoints, all async / internally parallel where safe (28 separate endpoints)
- All IO and LLM calls done async
- Pipeline stages are classes; 11
adaptersubclasses (Gemini Flash, Gemini Pro, GPT-4o, etc.). skipanduse_cachedflags run a no-op or reuse artefacts while the file tree stays unchanged.STAGE_DEPENDENCIESmapping declares primary & secondary inputs and outputs for every stage.- Hierarchical on-disk structure; files get a
_{revision_number}suffix for multi-round outputs. - Heavy use of controlled generation (using schemas)
- SQL instrumentation: All prompts, schemas, settings, outputs, latency, and errors logged to SQLite.
-
Frontend –
ContentTools(Next.js Server Components)- Specialised views:
- Book language adaptations
- Illustrate all artefacts of the adaptation pipeline (inputs, outpus)
- Easy debugging of what happened during the QA
- Easy comparisons between experimental implementations
- “Final for publish” view.
- Illustrations:
- All book illustrations as grids (chapters, chapter parts)
- Illustration deep dives - ideas and the best ideas
- Book language adaptations
- Reads JSON & WebP directly from disk—no extra HTTP hop.
- Specialised views:
-
CLI tools (all async friendly python)
- adaptation CLI
- Adapts and revises every chapter until it’s good enough
- Drives the pipeline stages implemented in the service (many endpoints right)
- Gracefully retries
- LLM driven decisions: Uses output from the overall review to finish the chapter or go for more rounds or partially skip stages
- narration CLI
- illustration CLI
- publishing CLI
- adaptation CLI
Everything runs locally, but could as well run on a server.
Yes, I ended up building a lightweight custom pipeline orchestration… 💀
Flow of a book adaptation with automatic QA (multiple revisions)
RAW BOOK
|
v
[book_stripping]
|
v
[chapter_extraction]
|
v
[chapter_simplification] (English)
|
v
[chapter_partification] (English)
| \
| \
| ---> [illustration_generation]
|
v
[adapt] ──▶ [Lang 1]
│ [Lang 2]
│ [Lang 3]
│ [Lang 4]
│ [Lang 5]
│ [Lang 6]
|
v
[review_chapter] ←──────────────┐
| │
v │
[revise_chapter] │
| │
v │
[review_consistency] │
| │
v │
[revise_consistency] │
| │
v │
[review_meaning_cohesion] │
| │
v │
[revise_meaning_cohesion] │
| │
v │
[review_titles] │
| │
v │
[revise_titles] │
| │
v │
[review_chapter_title] │
| │
v │
[revise_chapter_title] │
| │
v │
[review_overall] ──────────────┘
|
v
[promote_content]
|
|
+--> [book_narration] (from adapted text)
|
+--> [upload / publish]
QA rounds are controlled by the output of the review_overall stage.
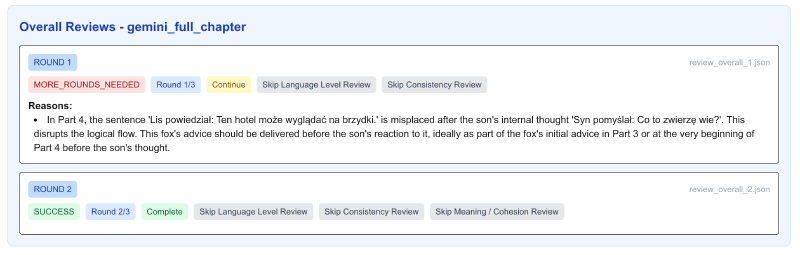
Examples of frontend enabling fast QA
Example of problematic images that can be ’easily spotted’ by a trained eye.
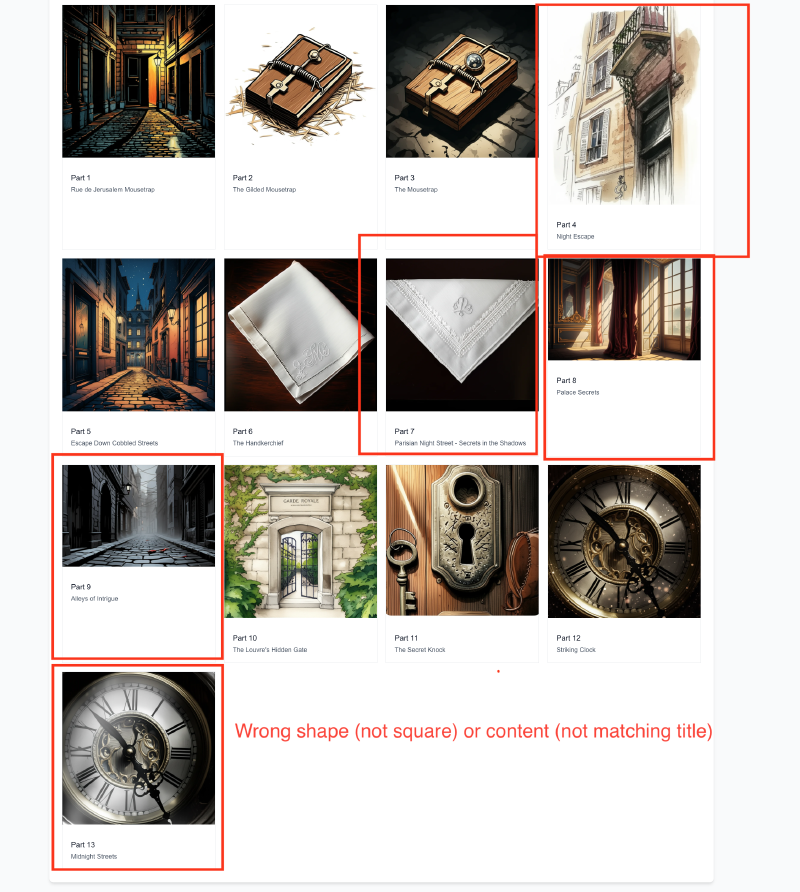
Chapter level issues overview for an adaptation workflow:
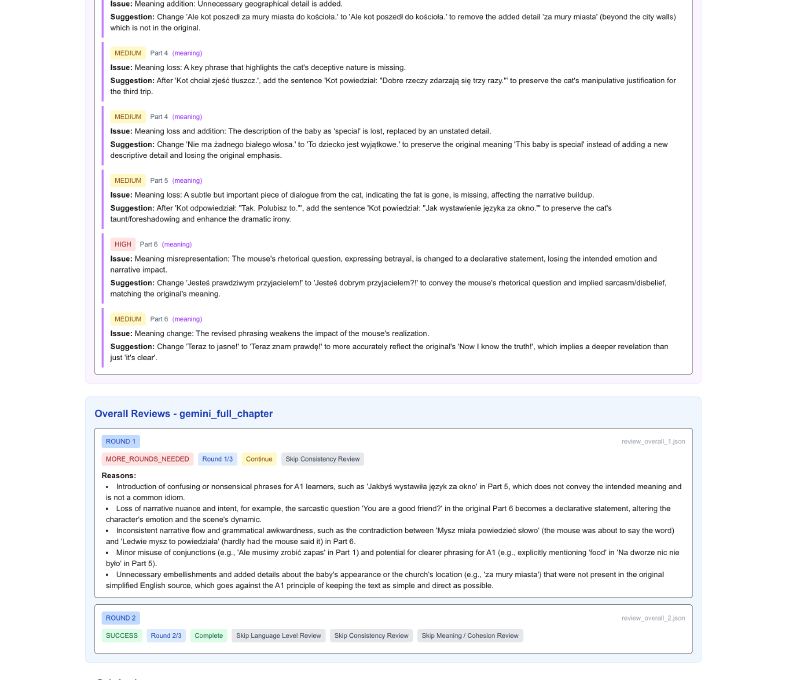
Part level debugging/review of what was suggested/applied in the QA pipeline:

Review and Revision—kept deliberately apart
One key design choice was to decouple “reviewer” from “reviser”.
The reviewer node reads the necessary context and produces a structured list of issues, while the reviser node sees only the affected slice plus those suggestions.
Why keep them separate?
-
Audit clarity
The reviewer’s JSON lives as its own artefact, so you can diff, grep, or hand-edit the feedback without touching the text itself. It’s also easier to audit automatic revisions and spot ‘additional helpfulness’. -
Smaller prompts, cheaper calls
A reviser that operates on just the target part + suggestions uses far fewer tokens than one that re-ingests the whole chapter. -
Less collateral damage
Narrow context means the reviser can’t “helpfully” rewrite good paragraphs in other sections or even just completely forget them. -
True parallelism
Parts are context-isolated, so multiple revisions can run concurrently—no giant chapter-wide lock. -
Targeted rollbacks
If a revision introduces a new issue, it’s easy to rollback.
What the flow looks like
-
review_meaning_cohesionscans consistency_revised_stories
and writesmeaning_cohesion_review_1.json:{ "issues": [ {{ "part_number": 1, "suggestion": "Change sentence '...sentence...' to '...corrected sentence...' to ensure consistency with previous parts.", "reason": "Inconsistent character name across parts.", "severity": "high" }}, ... ], } -
During the
revise_meaning_cohesionstage, revisions to specific parts are applied concurrently, e.g. reviser for part 8 only sees the text of part 8 and the suggestions for part 8.
Other novel elements
- Stable DAG via no-op nodes – skipping or caching never changes filenames or dependencies, so UI and controller logic stay simple.
- Declarative
STAGE_DEPENDENCIES– each endpoint validates its own inputs and fails fast if artefacts are missing. - Pluggable adapter subclasses – swapping models or prompt strategies is a config change, not a refactor.
- Direct-disk reading Server Side React Components – Suprisingly trivial frontend code.
- SQLite error forensics – a single query surfaces “prohibited-content” or other LLM failures.
- Hot-reload mid-run – tweak prompts or error handling while a 60-chapter fan-out is running; retries pick up the change without restart.
- WebP illustration storage – generated art compresses very well; files are roughly 10× smaller than raw outputs.
- LLM-driven controller decisions – the CLI uses the
review_overalloutput to decide whether to launch another revision round and which stages to skip.
Personal wins
The biggest win is defending my personal sanity.
I no longer have to babysit a set of fragile notebook based pipelines based on fallible and untrustworthy LLMs.
- Higher confidence in quality – every chapter passes level, consistency, meaning, and overall reviews—automatic multi-round fixes if needed.
- Far less toil – no more babysitting fragile notebooks; the pipeline self-checks and fails early.
- Fast, parallel experimentation – new adapters or prompts run side-by-side with hot-reload; iteration is “super fast and fun.”
- Cost flexibility – total spend is higher (as there are more LLM calls), but the modular design lets me fall back to cheaper or local models whenever I choose.
And the cool thing is that building this tooling was heavily accelerated by a coding assistant/agent, so it was significantly faster and more fun than I would have expected from the scope of the reengineering.